Towards Universal Navigation Foundation Models
This post reviews and summarizes the Embodied Navigation Foundation Model paper [Zhang et al., 2025], offering an independent overview and commentary on its approach to cross-embodiment and cross-task navigation.
Navigation meets Foundation Model
Classical navigation models are often limited to a single robot or task - a ground robot model can’t generalize to a drone or a language-guided setup. Meanwhile, foundation models in vision and language (like CLIP and GPT-4V) have shown that large-scale multi-modal pretraining can yield broad generalization. In parallel, recent advancements in Vision-Language-Action (VLA) models have shown promise for end-to-end autonomous driving, where large language models (LLMs) are integrated with perception and planning modules to perform end-to-end reasoning and planning.
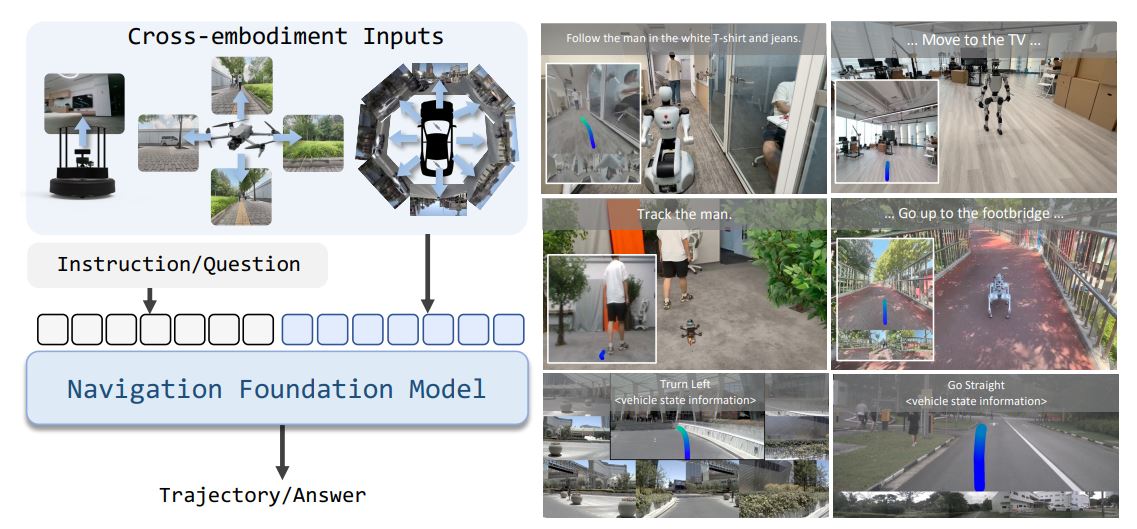
Inspired by this, Embodied Navigation Foundation Model introduced a cross-embodiment and cross-task navigation framework termed Navigation Foundation Model (NavFoM). NavFoM is trained on over eight million navigation samples spanning quadrupeds, drones, wheeled robots, and vehicles. The dataset covers a diverse set of tasks, including vision-and-language navigation, object searching, target tracking, and autonomous driving - allowing the model to generalize on cross-task and cross-embodiment.
The experiments show that the NavFoM - makes significant progress toward generalist navigation. Without any task-specific fine-tuning, the model achieves state-of-the-art or competitive performance across multiple public task benchmarks and robot embodiments.
Key results
-
VLN-CE RxR (Vision-Language Navigation)
- Multi-camera: 64.4% SR ↑ (from 56.3%)
- Single-camera: 57.4% SR ↑ (from 51.8%)
-
HM3D-OVON (Object-Goal Navigation)
- Zero-shot: 45.2% SR ↑ (from previous fine-tuned SOTA 43.%)
How the Model Works
NavFoM employs a unified architecture that processes multi-modal navigation inputs from varying camera configurations and navigation horizons. The authors introduces two key innovations: Temporal-Viewpoint Indicator (TVI) tokens, which encode camera viewpoint and temporal context, and Budget-Aware Temporal Sampling (BATS), which dynamically selects history tokens using a forgetting curve within a fixed token budget.
Architecture Overview
The model consists of four major components:
-
Vision Encoder - processes egocentric RGB from different camera configurations (single or multi-camera) based on DINOv2 and SigLip.
-
Cross-Modal projector - Vision encoder is followed by a cross-modal projector to align the image embeddings to the text embeddings.
-
Large Language Model - receives text instructions, projected image embeddings and temporal viewpoint indicator tokens and output tokens to the Action head. The model uses a pretrained large language model (LLM) backbone Qwen2-7B.
-
Trajectory prediction head - outputs continuous trajectory, normalized to [-1,1] and scaled according to the output task. Trajectory head is Implemented as a three-layer MLP.

Encoding temporal information and camera setup
Challenge: model must understand when and where (which view) each observation was captured.
A key challenge in multi-view navigation is that visual tokens alone don’t tell the model which camera or timestep they came from. To address this, NavFoM introduces Temporal-Viewpoint Indicator (TVI) tokens — lightweight learnable embeddings that tag each frame with both its viewpoint angle and its temporal position in the sequence.
Each TVI token combines three components:
-
Angle embedding: captures the camera’s azimuth in a circular way (0° ≡ 360°) so nearby viewpoints are geometrically close in embedding space.
-
Time embedding: marks the temporal order of frames, allowing reasoning over navigation history.
-
Base embedding: provides a consistent token structure that the model can adapt across different tasks (navigation, video QA, image QA).
This flexible design lets NavFoM process arbitrary camera configurations from single-view robots to panoramic car rigs, while maintaining clear separation between views and timestep.
Adapting to token budget
Challenge: Balancing long-term reasoning with limited compute and speed in real world
Long navigation sequences can produce thousands of visual tokens — far more than a transformer can handle efficiently for real time real world scenarios. To maintain temporal reasoning without exceeding memory limits, NavFoM introduces Budget-Aware Temporal Sampling (BATS).
Rather than treating every timestep equally, BATS applies a forgetting curve that assigns higher priority to recent frames and lower priority to distant ones. From all past frames {1, 2, …, T}, the model selects a subset B:
\[|\mathcal{S}(T)| = B, \quad \mathcal{S}(T) \subseteq \{1, 2, \ldots, T\}\]The forgetting curve is modeled as a simple exponential-like decay:
\[P(t, T) \propto e^{-\lambda (T - t)}\]This ensures the model maintains a constant token budget while focusing attention on the most recent and relevant observations. The result is a balanced temporal representation that achieves near-equivalent performance to full-sequence training while significantly reducing inference time.
Explore the sampling function:
Predicting a trajectory
Once the LLM produces its action embedding $E_T^A$, a lightweight Action Model $\mathcal{A}_\theta$ (a three-layer MLP) transforms it into a trajectory $\tau_T$ - a sequence of predicted waypoints describing future motion.
\[E_T^A = \mathrm{LLM}(E_{1:T}^{1:N}, E_L), \\ \tau_T = \mathrm{ActionModel}(E_T^A).\]To ensure stable behavior across embodiments (indoor navigation, UAVs, or cars), the predicted trajectory is normalized to the range $[-1, 1]$ and later rescaled by a task-specific factor $\alpha_{\text{task}}$. This prevents small prediction errors from exploding into large spatial deviations during waypoint rollout.
\[\tau_T = \{ \mathbf{a}_1, \ldots, \mathbf{a}_M \}_T = \alpha_{\text{task}} \cdot \mathcal{A}_\theta(E_T^A)\]The navigation loss is computed as the mean squared error (MSE) between the predicted and ground-truth waypoints:
\[L_{\text{nav}} = \mathrm{MSE}(\tau_T^{\text{idx}}, \tau_{\text{gt}}^{\text{idx}})\]Here, $\text{idx}$ represents the valid action dimensions:
- Cars / wheeled robots: $\mathbf{a}^{\text{idx}} = (x, y, \theta)$
- UAVs: $\mathbf{a}^{\text{idx}} = (x, y, z, \theta)$
The model jointly learns navigation and question-answering by combining losses:
\[L = \beta L_{\text{nav}} + L_{\text{QA}}\]where $\beta$ (set to 10) balances the navigation and QA terms. Because trajectory errors (MSE) are numerically small, $\beta$ amplifies their influence during optimization.
Learning from diverse navigation experiences
To train a foundation model capable of reasoning across embodiments and tasks, the author aggregate experience from multiple navigation datasets - spanning simulation, real-world driving, and language-conditioned control. Each dataset contributes a complementary view of embodied intelligence, from short-horizon indoor tasks to long-range, multi-agent driving.
Navigation data Composition
The navigation data is collected across multiple datasets from different domains including, Vision-and-language navigation, object goal navigation, active visual tracking and autonomous driving.
| Domain | Action Space | Trajectory Horizon (typ.) | Key features |
|---|---|---|---|
| Indoor | Discrete (F, L, R) | Short (meters) | Dense viewpoints, semantic goals |
| UAV | Continuous $(x,y,z,\theta)$ | Mid (10–30 m) | 3D motion, altitude & attitude control |
| Driving | Continuous $(x,y,\theta)$ | Long (20–80 m) | Multi-sensor context, traffic interaction |
| Total navigation scale: 8.02 M trajectories | |||
QA Datasets Composition
In addition to the navigation samples the model is trained to answer language QA corpora. The data include image QA, video QA
| QA Family | Count | Input Modality | Answer Space | What it teaches |
|---|---|---|---|---|
| Image QA | 3.15 M | Image + Question | Open-ended / MCQ | Object & attribute grounding, spatial relations, text-in-scene |
| Video QA | 1.61 M | Video + Question | Open-ended | Temporal events, causality, activity understanding |
| Total QA scale: 4.76 M Open-world understanding for perception & reasoning | ||||
Training Paradigm
The model was trained on a 56×H100 GPU cluster for about 72 hours (≈4,000 GPU hours). Frames from QA datasets were sampled at 1 FPS to minimize redundancy, while discrete navigation data (e.g., Habitat) were sampled per action step, and continuous navigation tasks (e.g., EVT-Bench, nuScenes) at 2 FPS for efficiency.
The visual encoders (DINOv2, SigLIP) and the language backbone (Qwen2-7B) were initialized from their pre-trained checkpoints. Following the standard VLM fine-tuning paradigm, only a subset of trainable parameters was fine-tuned for one epoch, ensuring efficient adaptation while preserving general multi-modal knowledge.
Deep-dive into main results
The authors trying to answer the following questions:
- Performance on diverse cross-benchmark navigation tasks
- Performance on real-world environments
- Effectiveness of key design choices
Visual language navigation benchmarks
VLN-CE vision-language navigation benchmark used to evaluate embodied agents that follow natural language instructions in realistic 3D environments. VLN visual-language-navigation and CE stands for continues 3d space environment.
The VLN dataset is composed of R2R dataset [Anderson et al., 2018] and RxR [Ku et al., 2020] dataset. Both datasets provide natural-language route instructions paired with ground-truth trajectories.
NavFoM managed to achieve SOTA results in both single camera and multi-camera configuration without training on the specific camera configuration and with no additional inputs that are used in other methods (depth and odo).
- VLN-CE RxR (Vision-Language Navigation)
- Multi-camera: 64.4% SR ↑ (from 56.3%)
- Single-camera: 57.4% SR ↑ (from 51.8%)
Success Rate (SR) measures how often the agent reaches the goal within a fixed distance threshold (commonly 3 m):
\[\text{SR} = \frac{1}{N} \sum_{i=1}^{N} \mathbf{1}\!\left[d\big(p_T^{(i)},\, p_{\text{goal}}^{(i)}\big) < \delta\right]\]OpenUAV benchmark
NavFoM was also evaluated on TravelUAV (Wang et al., 2024), a challenging drone navigation benchmark where agents must follow natural-language instructions to reach outdoor targets over long-horizon flights (~200 m).
Despite using only trajectories from the TravelUAV training split, without expert-collected supervision, NavFoM outperforms specialized UAV baselines, including TravelUAV itself, and does so without relying on downward-facing cameras.
Performance drops notably on the Unseen-Map split, which involves ~300 m flights through unseen neighborhoods. This highlights the remaining challenge of generalizing to large-scale, unseen outdoor environments, where richer UAV data and exploration strategies are needed.
OVON search benchmark
Object-Goal Vision-and-Language Navigation (OVON) is a challenging embodied navigation benchmarks, designed to test how well a single model can understand instructions, perceive scenes, and navigate to visual goals in 3D indoor environments.Unlike classical navigation tasks where the goal is a specific coordinate or room, OVON asks the model to find an object described in natural language - often open-vocabulary.
So the model must:
-
Ground language → parse what object is being asked for.
-
Perceive vision → detect potential object candidates.
-
Act → plan a trajectory that leads to that object.
Similar to VLN-CE benchmark NavFoM manages to achieve SOTA results comparing to the best zero shot method and comparable results to best non-zero shot method without training or finetuning on the specific dataset configuration.
- Single-camera:
- val-seen : 37.7% SR ↓ (from 55.0%)
- val-seen-synonym : 43.3% SR ↓ (from 45.0%)
- val-unseen : 43.6% SR ↑ (from 40.8%)
- Multi-camera:
- val-seen : 40.1% SR ↓ (from 55.0%)
- val-seen-synonym : 45.4% SR ↑ (from 45.0%)
- val-unseen : 45.2% SR ↑ (from 40.8%)
Tracking EVT-Bench benchmark
EVT-Bench (Embodied Visual Tracking Benchmark) is designed to evaluate an agent’s ability to visually track moving targets in embodied 3D environments. Unlike standard navigation tasks (where the goal is static), EVT-Bench requires continuous perception and motion control to follow a dynamic object, like another robot, human, or vehicle through realistic indoor or outdoor scenes.
It’s built within the Habitat simulation framework and includes both single-target and distracted-target settings:
- Single Target: The agent follows one moving target throughout the episode.
- Distracted Target: Multiple distractor objects appear; the agent must keep track of the correct one.
NavFoM was evaluated on EVT-Bench for both single target and distracted target splits, under single-view and four-view camera setups. Trained only in the single-view setting, it still achieves state-of-the-art performance, outperforming TrackVLA (Wang et al., 2025), which was fine-tuned for tracking. When tested zero-shot with four cameras, performance improves slightly (+0.6% SR), though less than the gains seen in VLN tasks. This modest increase is attributed to EVT-Bench’s design, where most targets already appear in front of the robot, limiting the benefit of multi-view inputs.
Autonomous driving benchmarks
NavSim is a simulated benchmark for embodied autonomous driving, built to study how agents plan and control vehicles from raw perception and language or goal inputs. It features diverse, photorealistic driving environments with multiple viewpoints, simulating complex navigation tasks such as lane following, intersection turns, and obstacle avoidance. Evaluation typically involves six or eight-camera configurations, enabling 360° perception around the ego vehicle.
NavFoM was evaluated on both NavSim and nuScenes under six and eight-view camera setups, without any configuration-specific fine-tuning. Despite not using explicit driving cues (like lane markings, traffic signals, or object tracking modules), NavFoM achieves performance comparable to state-of-the-art driving models on both benchmarks.
The results highlight the model’s strong cross-embodiment generalization - a single navigation foundation model trained across diverse tasks can perform competitively even in autonomous-driving scenarios.
The authors note that further gains could come from adding scene-level textual prompts (e.g., “follow the right lane and turn left at the intersection”), which may help integrate high-level reasoning with perception-driven control.
Key takeaways
-
Unified navigation model: NavFoM integrates multiple robot embodiments and multiple navigation tasks into a single cross-modal foundation model.
-
Efficient temporal encoding: Introduces Temporal-Viewpoint Indicator (TVI) tokens to help the LLM understand when and from which view each token was captured.
-
Compute-aware memory: The Budget-Aware Temporal Sampling (BATS) strategy maintains long-term temporal reasoning under fixed token limits, improving real-world efficiency.
-
Strong generalization: Achieves competitive or state-of-the-art performance across VLN, OVON, EVT-Bench, and NavSim, without task-specific fine-tuning.
-
Early step forward: As the author state “NavFoM serves merely as a starting point toward a navigation foundation model”.
-
Future work: NavFoM can be integrated with some ideas on recent article (Hydra-Next, DriveDPO, etc) to improve on the regression based trajectory head.
References
- [Zhang et al., 2025] Embodied Navigation Foundation Model
- [Oquab et al., 2024] DINOv2: Learning Robust Visual Features without Supervision
- [Zhai et al., 2023] SigLip
- [Wang et al., 2025] TrackVAL: Embodied Visual Tracking in the Wild
- [Liu et al., 2025] TrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
- [Li et al., 2025] Hydra-NeXt: Robust Closed-Loop Driving with Open-Loop Training
- [Shang et al., 2025] DriveDPO: Policy Learning via Safety DPO For End-to-End Autonomous Driving
Portnoy, D. (2025). Embodied-Drive.ai – Navigation meets foundation model.
https://doronpor.github.io/blog/2025/2025-10-13-NavFoM/